library(sf) # para trabajar con datos espaciales
library(dplyr) # para manipular datos en general
library(tidyr) # para transformar estructuras de datos
library(stringi) # para manipular texto
library(ggplot2) # para crear gráficos
library(readxl) # para leer nuestro archivo ExcelIntroducción
Si nunca has trabajado con mapas en R, es completamente normal que términos como SIG, Shapefile, GeoPackage, geometría o sistema de coordenadas suenen un poco intimidantes. La buena noticia es que, una vez comprendamos las ideas básicas, gran parte del trabajo se parece bastante a lo que ya hacemos normalmente en R: leer archivos, limpiar datos, unir tablas y hacer visualizaciones.
Primero entenderemos qué es un SIG y qué tipo de datos utiliza. Después veremos dos de los formatos vectoriales más comunes: el Shapefile y el GeoPackage. Finalmente, construiremos mapas coropléticos de México por estado; es decir, mapas donde cada estado se colorea de acuerdo con el valor de una variable.
Nota
En los SIG existen dos grandes tipos de datos espaciales:
- Vectoriales: Representan puntos, líneas y polígonos.
- Raster: Representan celdas o pixeles, como una imagen satelital o un modelo de elevación.
En este tutorial trabajaremos con datos vectoriales, porque los estados de México pueden representarse como polígonos.
¿Qué es un SIG?
Un Sistema de Información Geográfica (SIG) es un conjunto de herramientas que permite almacenar, organizar, analizar y visualizar datos que tienen una ubicación en el espacio. En palabras más simples, un SIG nos ayuda a trabajar con datos que viven en un mapa. Por ejemplo, con un SIG podríamos responder (visualmente) a preguntas como estas:
- ¿En qué estados hay mayor acceso a internet?
- ¿Qué municipios cuentan con mayor número de sucursales bancarias?
- ¿Cómo cambian ciertos indicadores entre regiones del país?
Tradicionalmente, estas tareas se realizan con programas especializados como QGIS o ArcGIS. Sin embargo, R también puede funcionar como un SIG muy potente, especialmente cuando queremos combinar análisis estadístico, limpieza de datos y visualización dentro del mismo flujo de trabajo.
R como SIG
Cuando usamos R como SIG, normalmente trabajamos con objetos espaciales que guardan dos cosas al mismo tiempo:
- un conjunto de atributos, es decir, información como nombres, claves o indicadores y
- una geometría, a saber, la forma y la ubicación espacial de cada observación.
El paquete más importante para esto hoy en día es {sf}. Las siglas vienen de simple features, un estándar moderno para representar datos espaciales vectoriales. Una de sus ventajas es que un objeto sf se comporta de manera muy parecida a un data frame, así que muchas operaciones con {dplyr} funcionan de manera natural.
Shapefiles y GeoPackages
Antes de dibujar nuestro primer mapa, vale la pena entender los formatos en los que suelen venir los datos espaciales.
Shapefile
El Shapefile es el formato más conocido en la comunidad geoespacial. Fue desarrollado por ESRI y durante muchos años ha sido el formato clásico para compartir y trabajar con capas vectoriales. Sin embargo, hay algo importante que suele confundir a quienes empiezan: un Shapefile no es realmente un solo archivo. En realidad, es un conjunto de archivos que trabajan juntos.
Los archivos más comunes son estos:
.shp: guarda la geometría;.shx: guarda un índice de la geometría;.dbf: guarda los atributos asociados en formato de tabla;.prj: guarda el sistema de coordenadas.
En términos estrictos, para que un shapefile funcione correctamente y conserve tanto la geometría como los atributos, al menos deben estar presentes los archivos .shp, .shx y .dbf. Sin embargo, en la práctica también conviene que esté presente el archivo .prj, porque sin él perdemos la referencia espacial del objeto y después pueden surgir problemas al intentar superponer esa capa con otras.
Es decir, cuando alguien te comparte un shapefile, normalmente en realidad te está compartiendo varios archivos al mismo tiempo. Si falta alguno de los esenciales, es muy probable que la capa no pueda abrirse correctamente o que se abra con información incompleta.
GeoPackage
El GeoPackage o GPKG es un formato más moderno. Internamente está basado en SQLite y fue diseñado como un estándar abierto para almacenar información geoespacial. Su principal ventaja es que todo queda guardado en un solo archivo con extensión .gpkg. Además, suele manejar mejor los nombres largos de variables, la codificación de texto y el almacenamiento de varias capas dentro del mismo archivo.
¿Cuál conviene usar?
Si necesitas máxima compatibilidad con software antiguo, el Shapefile sigue siendo útil. Empero, si estás empezando hoy y puedes elegir, el GeoPackage suele ser una mejor opción.
Preparación del Entorno de trabajo
Para este tutorial podríamos utilizar como fuente de información geoespacial directamente el Marco Geoestadístico 2025 del INEGI, que es la fuente oficial de referencia para la cartografía geoestadística de México. Sin embargo, para un primer acercamiento considero que esa descarga puede resultar algo pesada (245 MB), especialmente si nuestro objetivo inicial es simplemente aprender a leer una capa vectorial, entender su estructura y construir un mapa coroplético por entidad federativa. Por esa razón, en este tutorial utilizaremos una alternativa también oficial: la capa de División política estatal 1:250000. 2010 de CONABIO. Esta capa es mucho más ligera y suficiente para fines didácticos como los nuestros: el recurso en formato Shapefile (coordenadas geográficas) tiene un tamaño de 8.8 MB comprimido, lo cual la vuelve una opción mucho más manejable para aprender.
Ahora bien, nuestra variable de interés para el mapa coroplético será la pobreza por estado, definida de acuerdo con la tercera edición de la Metodología para la medición multidimensional de la pobreza del extinto Consejo Nacional de Evaluación de la Política de Desarrollo Social (CONEVAL). El anexo estadístico 2016 - 2022 proporciona los datos de porcentaje de población en pobreza (moderada y extrema) por entidad federativa, que serán los que utilizaremos para nuestros mapas. Para obtener esta información, podemos ir a la página del anexo antes mencionado y simplemente darle clic al botón llamado Anexo entidades federativas, lo cual descargará un archivo AE_estatal_2022.zip que contiene un archivo Excel llamado Anexo estad”stico entidades 2022.xlsx.
Una vez que ya tenemos claro qué información utilizaremos y de dónde obtendremos tanto la cartografía como la variable de interés, el siguiente paso es preparar nuestro entorno de trabajo en R. Para este tutorial utilizaremos seis paquetes principales:
El siguiente paso es importar los archivos que vamos a utilizar. Para simplificar el proceso, asumiré que tanto la carpeta que contiene el Shapefile extraída de AE_estatal_2022.zip llamada dest_2010gw, como el archivo de Excel se encuentran en la misma carpeta que el archivo .R, .Rmd o .qmd desde el cual estamos trabajando. Esta forma de organizar el proyecto es bastante útil cuando apenas estamos comenzando, porque nos permite leer los archivos directamente por su nombre, sin necesidad de escribir rutas más largas o complejas. Si quisiéramos organizar nuestro proyecto de una manera más estructurada, podríamos crear subcarpetas como data para guardar nuestros archivos de datos, y entonces la ruta para leer el Shapefile sería algo así como data/dest_2010gw/dest_2010gw.shp, y para el Excel sería data/Anexo estadístico entidades 2022.xlsx. Sin embargo, para este tutorial mantendremos las cosas simples y asumiremos que ambos archivos están en la raíz del proyecto.
Primero comenzaremos importando el Shapefile. Como ya se mencionó antes, aunque un Shapefile está compuesto por varios archivos, para leerlo en R basta con indicar la ruta del archivo .shp, siempre y cuando los demás componentes esenciales se encuentren en la misma carpeta. En nuestro caso, como la carpeta dest_2010gw está en la raíz del proyecto, podemos importarlo de la siguiente manera:
mapa_mexico <- st_read("dest_2010gw/dest_2010gw.shp")Reading layer `dest_2010gw' from data source
`/Users/ale_romero/Library/CloudStorage/OneDrive-CIDE/R/AlejandroRomeroG.github.io/blog/RComoSIG-Mapa/dest_2010gw/dest_2010gw.shp'
using driver `ESRI Shapefile'
Simple feature collection with 1212 features and 8 fields
Geometry type: POLYGON
Dimension: XY
Bounding box: xmin: -118.3665 ymin: 14.53496 xmax: -86.71074 ymax: 32.71873
Geodetic CRS: WGS 84Si todo salió bien, R nos mostrará en la consola un breve resumen del objeto espacial que acabamos de importar: el número de observaciones (features), el número de variables (fields), el tipo de geometría, la extensión espacial del objeto y el sistema de referencia de coordenadas. En este caso, veremos que la capa se encuentra en el sistema WGS 84, uno de los más comunes para trabajar con información geográfica. Para inspeccionar con más detalle el objeto importado y sus atributos, basta con escribir su nombre:
mapa_mexicoSimple feature collection with 1212 features and 8 fields
Geometry type: POLYGON
Dimension: XY
Bounding box: xmin: -118.3665 ymin: 14.53496 xmax: -86.71074 ymax: 32.71873
Geodetic CRS: WGS 84
First 10 features:
AREA PERIMETER COV_ COV_ID ENTIDAD CAPITAL RASGO_GEOG
1 7.171369e+10 2273088.5899 2 1 BAJA CALIFORNIA Mexicali <NA>
2 4.778415e+05 3517.5845 3 2 BAJA CALIFORNIA <NA> ISLA
3 4.242857e+04 916.2356 4 3 BAJA CALIFORNIA <NA> ISLA
4 1.297501e+05 2259.5981 5 4 BAJA CALIFORNIA <NA> ISLA
5 1.479776e+06 7917.4943 6 5 BAJA CALIFORNIA <NA> ISLA
6 1.792021e+11 3759999.3858 7 6 SONORA Hermosillo <NA>
7 1.341048e+08 70456.4252 8 7 BAJA CALIFORNIA <NA> ISLA
8 1.617167e+07 18779.8250 9 8 BAJA CALIFORNIA <NA> ISLA
9 2.469928e+11 3119522.9908 10 9 CHIHUAHUA Chihuahua <NA>
10 1.498113e+05 1522.8309 11 10 BAJA CALIFORNIA <NA> ISLA
NUM_EDO geometry
1 02 POLYGON ((-117.0825 32.3816...
2 02 POLYGON ((-117.2944 32.4341...
3 02 POLYGON ((-117.2629 32.4233...
4 02 POLYGON ((-117.2595 32.4148...
5 02 POLYGON ((-117.2396 32.3907...
6 26 POLYGON ((-114.8133 32.4925...
7 02 POLYGON ((-114.7069 31.7452...
8 02 POLYGON ((-114.6085 31.7284...
9 08 POLYGON ((-108.7544 31.3346...
10 02 POLYGON ((-116.0428 30.7120...En este punto conviene detenernos un momento a observar qué acabamos de importar. Como puede verse, mapa_mexico no es un data frame cualquiera, sino un objeto de clase sf. Esto significa que, además de los atributos de cada entidad federativa, también contiene la geometría correspondiente a cada una de ellas. Entre las variables disponibles, la más importante para nuestros propósitos será ENTIDAD, ya que contiene el nombre de cada estado y nos servirá más adelante para unir la cartografía con la base de pobreza.
Si queremos echar un primer vistazo visual a la cartografía, podemos graficar únicamente la geometría:
plot(st_geometry(mapa_mexico))
Este gráfico todavía es muy básico, pero nos permite comprobar rápidamente que la capa se importó correctamente y que la geometría de las entidades federativas luce razonable. El siguiente paso es importar el archivo de Excel que contiene la información de pobreza. Antes de leerlo, conviene revisar qué hojas contiene:
excel_sheets("Anexo estad”stico entidades 2022.xlsx") [1] "Contenido" "Estados Unidos Mexicanos"
[3] "Aguascalientes" "Baja California"
[5] "Baja California Sur" "Campeche"
[7] "Coahuila de Zaragoza" "Colima"
[9] "Chiapas" "Chihuahua"
[11] "Ciudad de México" "Durango"
[13] "Guanajuato" "Guerrero"
[15] "Hidalgo" "Jalisco"
[17] "México" "Michoacán de Ocampo"
[19] "Morelos" "Nayarit"
[21] "Nuevo León" "Oaxaca"
[23] "Puebla" "Querétaro"
[25] "Quintana Roo" "San Luis Potosí"
[27] "Sinaloa" "Sonora"
[29] "Tabasco" "Tamaulipas"
[31] "Tlaxcala" "Veracruz de Ignacio de la Llave"
[33] "Yucatán" "Zacatecas" Al hacer esto veremos que el archivo no contiene una sola tabla con toda la información junta, sino varias hojas: una de contenido, una para el total nacional y una hoja para cada entidad federativa. Esta estructura no es tan cómoda como una base rectangular tradicional, pero sigue siendo perfectamente utilizable. De hecho, nos permitirá construir nosotros mismos una pequeña base de datos estatal a partir de cada hoja. Para entender mejor cómo está organizado el archivo, podemos importar primero una sola hoja, por ejemplo la de Aguascalientes:
aguascalientes_raw <- read_excel(
"Anexo estad”stico entidades 2022.xlsx",
sheet = "Aguascalientes",
col_names = FALSE
)
aguascalientes_raw# A tibble: 28 × 17
...1 ...2 ...3 ...4 ...5 ...6 ...7 ...8 ...9 ...10 ...11
<chr> <lgl> <chr> <chr> <dbl> <dbl> <chr> <lgl> <chr> <dbl> <dbl>
1 Medición … NA <NA> <NA> NA NA <NA> NA <NA> NA NA
2 Porcentaj… NA <NA> <NA> NA NA <NA> NA <NA> NA NA
3 <NA> NA Indi… Porc… NA NA <NA> NA Mile… NA NA
4 <NA> NA <NA> 2016 2018 2020 2022… NA 2016 2018 2020
5 <NA> NA Pobr… <NA> NA NA <NA> NA <NA> NA NA
6 <NA> NA Pobl… 28.9… 26.3 27.6 23.7… NA 381.… 361. 396.
7 <NA> NA Pobl… 26.7… 25.3 25.2 21.9… NA 352.… 347. 362.
8 <NA> NA Pobl… 2.21… 0.988 2.42 1.75… NA 29.2… 13.6 34.7
9 <NA> NA Pobl… 25.1… 25.5 25.6 29.8… NA 330.… 351. 367.
10 <NA> NA Pobl… 11.5… 12.0 11.1 9.25… NA 152.… 165. 159.
# ℹ 18 more rows
# ℹ 6 more variables: ...12 <chr>, ...13 <lgl>, ...14 <chr>, ...15 <dbl>,
# ...16 <dbl>, ...17 <chr>Si observamos esta hoja con cuidado, notaremos que la fila que nos interesa es la correspondiente a Población en situación de pobreza, mientras que las columnas que nos interesan son las de los años 2016, 2018, 2020 y 2022 dentro del bloque de porcentajes. Es decir, lo que haremos a continuación será repetir esta misma extracción para cada una de las hojas estatales. Primero obtenemos los nombres de todas las hojas y descartamos aquellas que no representan una entidad federativa:
hojas <- excel_sheets("Anexo estad”stico entidades 2022.xlsx")
hojas_estados <- hojas[!(hojas %in% c("Contenido", "Estados Unidos Mexicanos"))]
hojas_estados [1] "Aguascalientes" "Baja California"
[3] "Baja California Sur" "Campeche"
[5] "Coahuila de Zaragoza" "Colima"
[7] "Chiapas" "Chihuahua"
[9] "Ciudad de México" "Durango"
[11] "Guanajuato" "Guerrero"
[13] "Hidalgo" "Jalisco"
[15] "México" "Michoacán de Ocampo"
[17] "Morelos" "Nayarit"
[19] "Nuevo León" "Oaxaca"
[21] "Puebla" "Querétaro"
[23] "Quintana Roo" "San Luis Potosí"
[25] "Sinaloa" "Sonora"
[27] "Tabasco" "Tamaulipas"
[29] "Tlaxcala" "Veracruz de Ignacio de la Llave"
[31] "Yucatán" "Zacatecas" Ahora construiremos una pequeña función que lea cada hoja estatal, localice la fila de Población en situación de pobreza y extraiga el porcentaje correspondiente a 2016, 2018, 2020 y 2022, respectivamente. En este archivo, esa información se encuentra en la tercera columna para el nombre del indicador y en la cuarta, quinta, sexta y séptima columna para el porcentaje de los años ya mencionados.
extraer_pobreza <- function(hoja) {
tabla <- read_excel(
"Anexo estad”stico entidades 2022.xlsx",
sheet = hoja,
col_names = FALSE
)
fila_pobreza <- which(tabla[[3]] == "Población en situación de pobreza")[1]
data.frame(
ENTIDAD = hoja,
pobreza_2016 = as.numeric(tabla[[4]][fila_pobreza]),
pobreza_2018 = as.numeric(tabla[[5]][fila_pobreza]),
pobreza_2020 = as.numeric(tabla[[6]][fila_pobreza]),
pobreza_2022 = as.numeric(tabla[[7]][fila_pobreza])
)
}Con esa función lista, ya podemos aplicarla a todas las hojas estatales y reunir el resultado en una sola base:
pobreza_estados <- bind_rows(lapply(hojas_estados, extraer_pobreza))
pobreza_estados ENTIDAD pobreza_2016 pobreza_2018 pobreza_2020
1 Aguascalientes 28.94648 26.26541 27.62669
2 Baja California 22.60487 23.59869 22.51012
3 Baja California Sur 22.88005 18.57216 27.60222
4 Campeche 45.66019 48.96430 50.54915
5 Coahuila de Zaragoza 27.05571 25.50771 25.61704
6 Colima 32.53320 30.41075 26.69353
7 Chiapas 77.91276 77.99502 75.49129
8 Chihuahua 30.70164 26.64279 25.30499
9 Ciudad de México 26.59985 29.96781 32.60447
10 Durango 37.19312 38.78717 38.69167
11 Guanajuato 39.35110 41.48813 42.74239
12 Guerrero 66.82816 67.89002 66.40571
13 Hidalgo 56.90224 49.86971 50.75079
14 Jalisco 30.46840 27.80150 31.41550
15 México 46.64539 41.77450 48.86456
16 Michoacán de Ocampo 54.16250 46.21151 44.50929
17 Morelos 46.69338 48.54414 50.94579
18 Nayarit 38.10435 35.72054 30.40544
19 Nuevo León 18.84034 19.38327 24.33040
20 Oaxaca 67.97761 64.33596 61.66425
21 Puebla 58.12609 58.00944 62.43210
22 Querétaro 29.68809 26.37347 31.32530
23 Quintana Roo 31.65285 30.19206 47.48029
24 San Luis Potosí 44.13719 42.06817 42.84615
25 Sinaloa 30.45804 30.98426 28.07140
26 Sonora 27.00777 26.66402 29.92402
27 Tabasco 53.84361 56.35136 54.47779
28 Tamaulipas 32.04342 34.54683 34.94246
29 Tlaxcala 55.93331 50.96552 59.28752
30 Veracruz de Ignacio de la Llave 60.49191 60.15534 58.60315
31 Yucatán 45.50457 44.03003 49.48563
32 Zacatecas 50.19457 49.23215 45.77076
pobreza_2022
1 23.72232
2 13.37082
3 13.32903
4 45.12944
5 18.24332
6 20.54717
7 67.37083
8 17.57220
9 23.96761
10 34.31107
11 33.03430
12 60.35474
13 40.99902
14 21.83615
15 42.87551
16 41.73628
17 41.05589
18 29.31316
19 16.04045
20 58.44035
21 54.01727
22 21.69072
23 26.96601
24 35.52276
25 21.63881
26 21.69311
27 46.47409
28 26.82275
29 52.51998
30 51.73243
31 38.77263
32 44.21589En este punto ya contamos con una base de datos mucho más cómoda para trabajar los datos de pobreza. pobreza_estados tiene una fila por entidad federativa y una columna para cada año de interés. A primera vista, podría parecer que ya estamos listos para unir esta tabla con la cartografía. Sin embargo, antes de hacerlo conviene verificar que los nombres de las entidades coincidan correctamente en ambas fuentes. Podemos revisar rápidamente los nombres únicos de cada base con las siguientes instrucciones:
sort(unique(mapa_mexico$ENTIDAD)) [1] "AGUASCALIENTES" "BAJA CALIFORNIA"
[3] "BAJA CALIFORNIA SUR" "CAMPECHE"
[5] "CHIAPAS" "CHIHUAHUA"
[7] "COAHUILA DE ZARAGOZA" "COLIMA"
[9] "DISTRITO FEDERAL" "DURANGO"
[11] "GUANAJUATO" "GUERRERO"
[13] "HIDALGO" "JALISCO"
[15] "MEXICO" "MICHOACAN DE OCAMPO"
[17] "MORELOS" "NAYARIT"
[19] "NUEVO LEON" "OAXACA"
[21] "PUEBLA" "QUERETARO DE ARTEAGA"
[23] "QUINTANA ROO" "SAN LUIS POTOSI"
[25] "SINALOA" "SONORA"
[27] "TABASCO" "TAMAULIPAS"
[29] "TLAXCALA" "VERACRUZ DE IGNACIO DE LA LLAVE"
[31] "YUCATAN" "ZACATECAS" sort(unique(pobreza_estados$ENTIDAD)) [1] "Aguascalientes" "Baja California"
[3] "Baja California Sur" "Campeche"
[5] "Chiapas" "Chihuahua"
[7] "Ciudad de México" "Coahuila de Zaragoza"
[9] "Colima" "Durango"
[11] "Guanajuato" "Guerrero"
[13] "Hidalgo" "Jalisco"
[15] "México" "Michoacán de Ocampo"
[17] "Morelos" "Nayarit"
[19] "Nuevo León" "Oaxaca"
[21] "Puebla" "Querétaro"
[23] "Quintana Roo" "San Luis Potosí"
[25] "Sinaloa" "Sonora"
[27] "Tabasco" "Tamaulipas"
[29] "Tlaxcala" "Veracruz de Ignacio de la Llave"
[31] "Yucatán" "Zacatecas" Si observamos ambas salidas con cuidado, veremos que los nombres no coinciden de forma exacta. Esto ocurre porque la cartografía de CONABIO utiliza mayúsculas, omite algunos acentos y además conserva nombres administrativos más antiguos, como DISTRITO FEDERAL; mientras que el archivo de pobreza usa nombres más recientes, como Ciudad de México. Para resolver este problema, crearemos una pequeña función que estandarice los nombres de las entidades en ambas bases.
normalizar_entidad <- function(x) {
x <- stri_trans_general(x, "Latin-ASCII") # Elimina acentos
x <- toupper(x) # Convierte a mayúsculas
x <- trimws(x) # Elimina espacios en blanco al inicio y al final
x <- case_when( # Reemplaza nombres específicos
x == "DISTRITO FEDERAL" ~ "CIUDAD DE MEXICO",
x == "QUERETARO DE ARTEAGA" ~ "QUERETARO",
TRUE ~ x
)
return(x)
}Aplicamos ahora esta función tanto a la cartografía como a la base de pobreza:
mapa_mexico <- mapa_mexico |>
mutate(ENTIDAD_STD = normalizar_entidad(ENTIDAD))
pobreza_estados <- pobreza_estados |>
mutate(ENTIDAD_STD = normalizar_entidad(ENTIDAD))Con esto ya podemos unir ambas fuentes de información utilizando la nueva variable ENTIDAD_STD como llave:
mapa_pobreza <- mapa_mexico |>
left_join(
pobreza_estados |>
select(ENTIDAD_STD, pobreza_2016, pobreza_2018, pobreza_2020, pobreza_2022),
by = "ENTIDAD_STD"
)Construcción de mapas coropléticos
Ahora pasemos a la parte más visual del tutorial. Como ya tenemos la geometría de cada entidad y el porcentaje de población en pobreza para varios años dentro de un mismo objeto sf, podemos comenzar construyendo un primer mapa para 2016. La lógica de {ggplot2} en este caso es bastante simple: usaremos geom_sf() para dibujar las entidades federativas y asignaremos la variable pobreza_2016 al argumento fill, que controla el color de relleno de cada polígono.
mapa_2016 <- ggplot(mapa_pobreza) +
geom_sf(aes(fill = pobreza_2016), color = "white", linewidth = 0.2) +
scale_fill_gradient(
low = "#FDFBF7",
high = "#9158A2",
name = "Pobreza (%)"
) +
labs(
title = "Porcentaje de población en situación de pobreza por entidad federativa",
subtitle = "México, 2016",
caption = "Fuente: Elaboración propia con datos de CONEVAL y geometrías de CONABIO"
) +
theme_void() +
theme(
plot.title = element_text(face = "bold", size = 14),
plot.subtitle = element_text(size = 12),
plot.caption = element_text(size = 10),
legend.position = "right"
)
mapa_2016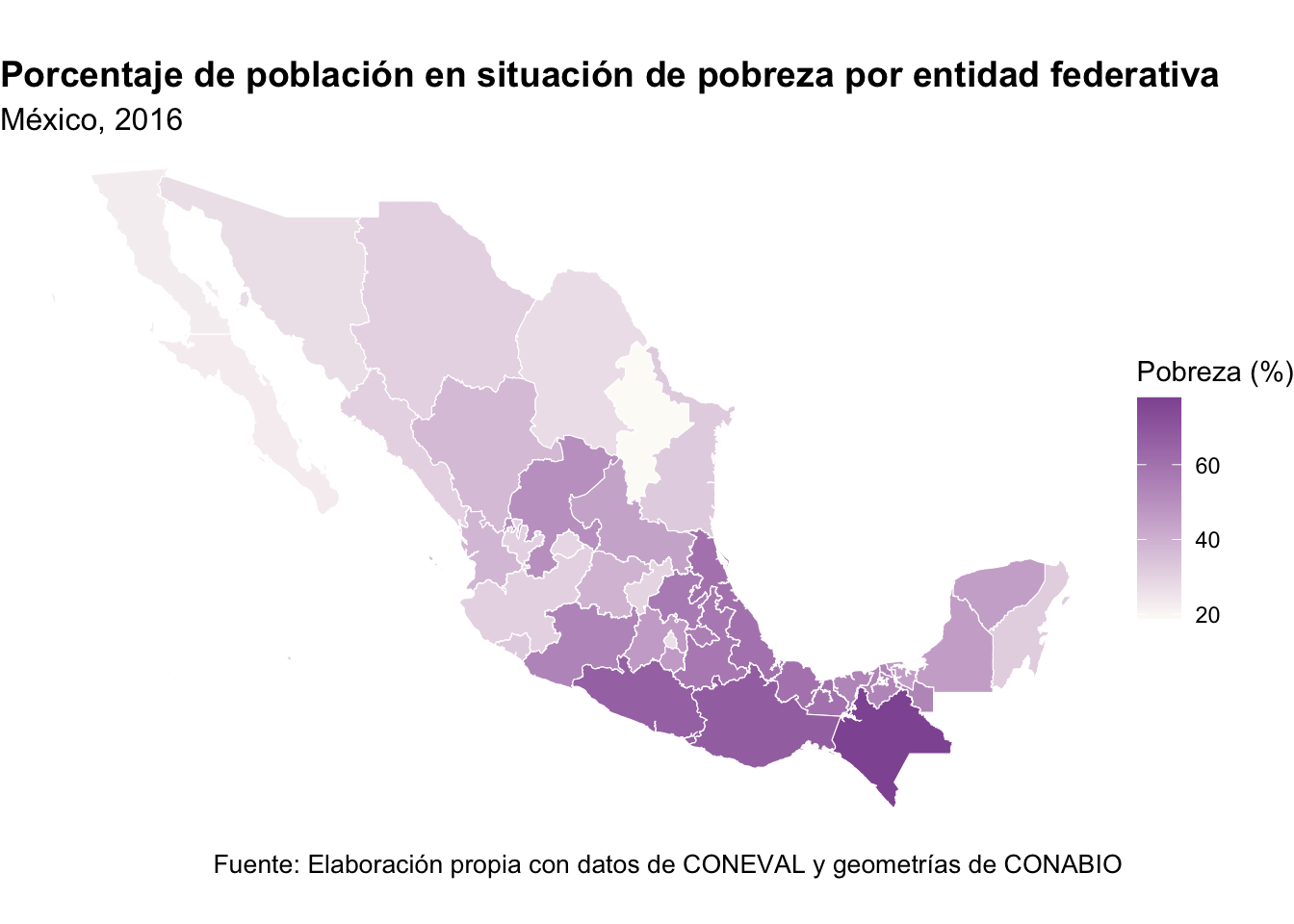
El resultado es ya un mapa coroplético funcional: cada estado aparece coloreado según su porcentaje de población en situación de pobreza. Los tonos más claros representan menores niveles de pobreza, mientras que los tonos más intensos corresponden a valores más altos. Una ventaja adicional de haber extraído los datos para más de un año es que podemos repetir este mismo procedimiento para 2018, 2020 o 2022, simplemente cambiando la variable utilizada en fill. Por ejemplo, para mapear 2022 bastaría con reemplazar pobreza_2016 por pobreza_2022 y cambiar el subtítulo:
mapa_2022 <- ggplot(mapa_pobreza) +
geom_sf(aes(fill = pobreza_2022), color = "white", linewidth = 0.2) +
scale_fill_gradient(
low = "#FDFBF7",
high = "#9158A2",
name = "Pobreza (%)"
) +
labs(
title = "Porcentaje de población en situación de pobreza por entidad federativa",
subtitle = "México, 2022",
caption = "Fuente: Elaboración propia con datos de CONEVAL y geometrías de CONABIO"
) +
theme_void() +
theme(
plot.title = element_text(face = "bold", size = 14),
plot.subtitle = element_text(size = 12),
plot.caption = element_text(size = 10),
legend.position = "right"
)
mapa_2022
A bote pronto, con fines de comparación, podríamos poner una imagen al lado de la otra en cualquier documento para sacar conclusiones. Sin embargo, estaríamos cometiendo un error común en la visualización de datos: comparar mapas coropléticos sin una escala de colores común. En el ejemplo anterior, cada mapa tiene su propia escala de colores, lo que puede llevar a interpretaciones erróneas. Por ejemplo, un estado que tenga el mismo porcentaje de población en situación de pobreza en ambos años podría aparecer con un color diferente si las escalas no son idénticas (los valores mínimos y máximos cambian), lo que podría hacer pensar que hubo un cambio cuando en realidad no lo hubo. Para evitar esto, es fundamental establecer una escala de colores común para todos los mapas que se quieran comparar.
Para resolver este problema, primero debemos calcular un rango común de valores que abarque todos los años que queremos comparar. De esta manera, cada color representará exactamente el mismo nivel de pobreza en todos los mapas.
limites_pobreza <- range(
c(
mapa_pobreza$pobreza_2016,
mapa_pobreza$pobreza_2018,
mapa_pobreza$pobreza_2020,
mapa_pobreza$pobreza_2022
),
na.rm = TRUE
)
limites_pobreza[1] 13.32903 77.99502En lugar de construir cada mapa por separado y luego intentar acomodarlos manualmente, una alternativa más elegante consiste en reorganizar la base de datos a un formato largo. Así, cada observación conservará su geometría, pero además tendrá una nueva variable que indique el año correspondiente. Esto nos permitirá utilizar facet_wrap() para generar los cuatro mapas dentro de una sola figura. Para esto, usaremos la función pivot_longer() del paquete {tidyr}:
mapa_pobreza_largo <- mapa_pobreza |>
select(geometry, pobreza_2016, pobreza_2018, pobreza_2020, pobreza_2022) |>
pivot_longer(
cols = starts_with("pobreza_"),
names_to = "anio",
values_to = "pobreza"
) |>
mutate(
anio = factor(
anio,
levels = c("pobreza_2016", "pobreza_2018", "pobreza_2020", "pobreza_2022"),
labels = c("2016", "2018", "2020", "2022")
)
) |>
st_as_sf()Con esta nueva base ya podemos construir una sola imagen con los cuatro mapas en una disposición de 2 por 2: en la primera fila aparecerán 2016 y 2018, y en la segunda 2020 y 2022.
mapa_comparativo <- ggplot(mapa_pobreza_largo) +
geom_sf(aes(fill = pobreza), color = "white", linewidth = 0.2) +
scale_fill_gradient(
low = "#FDFBF7",
high = "#9158A2",
limits = limites_pobreza,
name = "Pobreza (%)"
) +
facet_wrap(~anio, ncol = 2) +
labs(
title = "Porcentaje de población en situación de pobreza por entidad federativa",
subtitle = "México, 2016-2022",
caption = "Fuente: Elaboración propia con datos de CONEVAL y geometrías de CONABIO"
) +
theme_void() +
theme(
strip.text = element_text(face = "bold", size = 11),
plot.title = element_text(face = "bold", size = 14, hjust = 0.5),
plot.subtitle = element_text(size = 12, hjust = 0.5),
plot.caption = element_text(size = 10),
legend.position = "bottom"
)
mapa_comparativo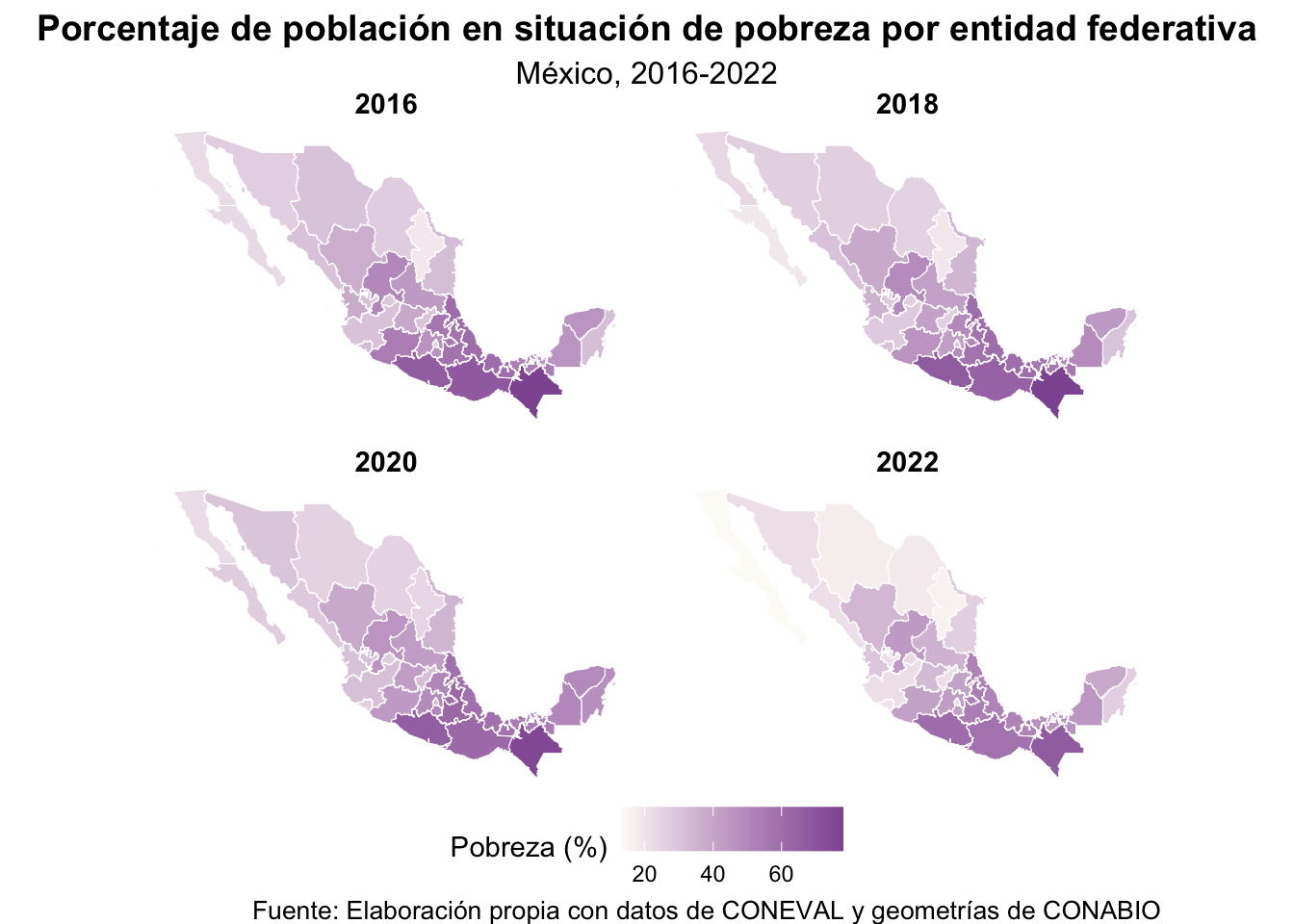
El resultado es una sola figura comparativa con una escala de colores común, una sola leyenda y un encabezado compartido. De esta manera, cualquier diferencia visual entre los paneles refleja cambios reales en la pobreza y no simples variaciones en la escala de color. Finalmente, para guardar la visualización como archivo de imagen utilizaremos la función ggsave(), que permite exportar objetos creados con {ggplot2} en distintos formatos:
ggsave(filename = "mapa.png", plot = mapa_comparativo,
width = 7, height = 5, dpi = 300, bg = "white")Si preferimos guardarla como JPG, basta con cambiar la extensión del archivo:
ggsave(filename = "mapa.jpg", plot = mapa_comparativo,
width = 7, height = 5, dpi = 300, bg = "white")En ambos casos, width y height controlan el tamaño de la imagen, mientras que dpi determina su resolución. Un valor de 300 en este último campo suele ser suficiente para obtener una imagen de buena calidad tanto en pantalla como en impresión.
Conclusión
A lo largo de este tutorial vimos que R puede utilizarse como un Sistema de Información Geográfica bastante potente. Primero entendimos qué es un SIG y repasamos la diferencia entre Shapefiles y GeoPackages, dos de los formatos vectoriales más comunes en el trabajo geoespacial. Después importamos una capa cartográfica, construimos una base de datos estatal de pobreza a partir de un archivo de Excel, estandarizamos nombres de entidades, unimos ambas fuentes y, finalmente, creamos un mapa coroplético comparativo para distintos años.
Más allá de los mapas en sí, lo más importante aquí fue el flujo de trabajo que aprendimos: importar datos espaciales, limpiar datos tabulares, unir ambas fuentes y visualizarlas correctamente. Una vez entendido este proceso, resulta relativamente sencillo repetirlo con otras variables, otras escalas geográficas o incluso otras fuentes de información. En ese sentido, R no solo sirve para hacer mapas, sino para integrar análisis espacial y análisis de datos dentro de un mismo entorno de trabajo.